Pix2Pix - Image to image translation with Conditional Adversarial Networks
A tutorial on Pix2Pix Conditional GANs and implementation with PyTorch



Author Introduction
Hi! My name is Aniket Maurya. I am a Machine Learning Engineer at Quinbay Technologies, India. I research and build ML products. I like to share my limited knowledge of Machine Learning and Deep Learning with on my blog or YouTube channel.You can connect with me on Linkedin/Twitter.
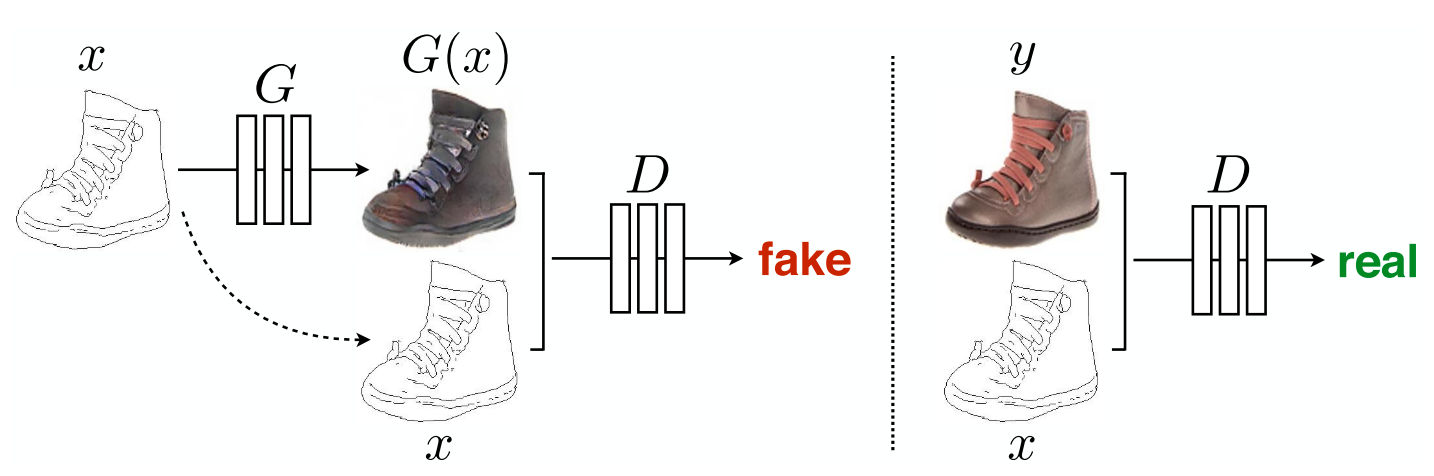
Image to Image translation means transforming the given source image into a different image. Gray scale image to colour image conversion is one such example of image of image translation.
In this tutorial we will discuss GANs, a few points from Pix2Pix paper and implement the Pix2Pix network to translate segmented facade into real pictures. We will create the Pix2Pix model in PyTorch and use PyTorch lightning to avoid boilerplates.
Authors of Image-to-Image Translation with Conditional Adversarial Networks paper has also made the source code publically available on GitHub.> A more detailed tutorial on GANs can be found here - Yann LeCun’s Deep Learning Course at CDS
GANs are Generative models that learns a mapping from random noise vector (z) to an output image.
G(z) -> Image (y)
For example, GANs can learn mapping from random normal vectors to generate smiley images. For training such a GAN we just need a set of smiley images and train the GAN with an adversarial loss 🙂. After the model is trained we can use random normal noise vectors to generate images that were not in the training dataset.
But what if we want to build a network in such a way that we can control what the model will generate. In our case we want the model to generate a laughing smiley.
Conditional GANs are Generative networks which learn mapping from random noise vectors and a conditional vector to output an image.
Suppose we have 4 types of smileys - smile, laugh, sad and angry (🙂 😂 😔 😡). So our class vector for smile 🙂 can be (1,0,0,0), laugh can be 😂 (0,1,0,0) and similarly for others.
Here the conditional vector is the smiley embedding.
During training of the generator the conditional image is passed to the generator and fake image is generated. The fake image is then passed through the discriminator along with the conditional image, both fake image and conditional image are concatenated. Discriminator penalizes the generator if it correctly classifies the fake image as fake.
Pix2Pix is an image-to-image translation Generative Adversarial Networks that learns a mapping from an image X and a random noise Z to output image Y or in simple language it learns to translate the source image into a different distribution of image.
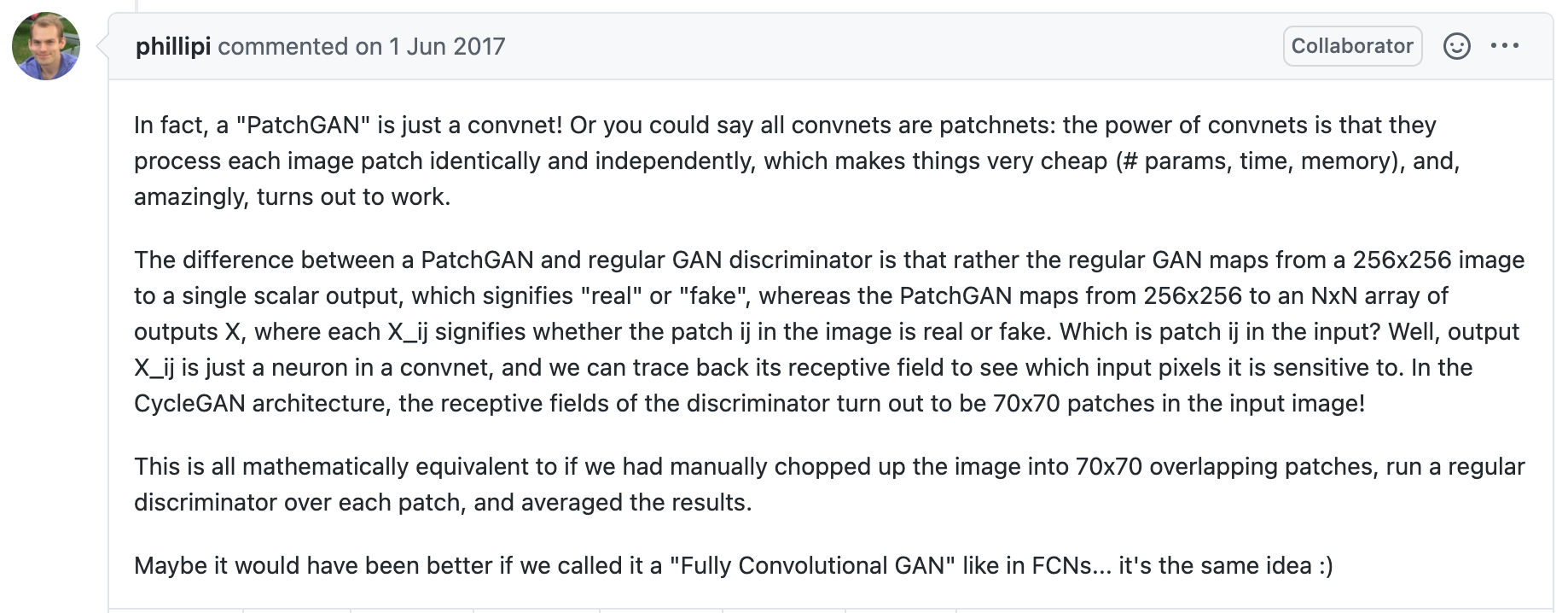
During the time Pix2Pix was released, several other works were also using Conditional GANs on discrete labels. Pix2Pix uses a U-Net based architecture for the Generator and for the Discriminator a PatchGAN Classifier is used.
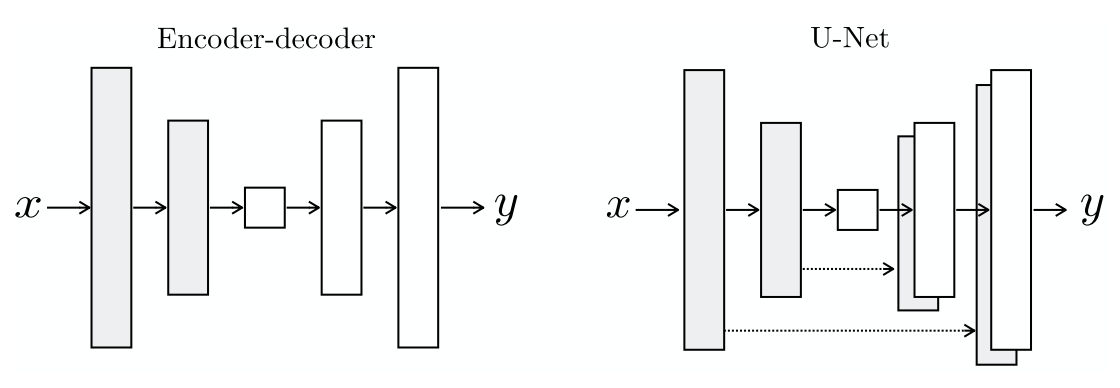
Pix2Pix Generator is an U-Net based architecture which is an encoder-decoder network with skip connections. The name U-Net highlights the structure of the "U" shaped network. Both generator and discriminator uses Convolution-BatchNorm-ReLu like module or in simple words we can say that it is the unit block of the generator and discriminator.
Skip connections are added between each layer i and layer n−i, where n is the total number of layers. At each skip connection all the channels from current layer i are concatenated with all the channels at n-i layer.
Lets understand it more with code.
import os
from glob import glob
from pathlib import Path
import matplotlib.pyplot as plt
import pytorch_lightning as pl
import torch
from PIL import Image
from torch import nn
from torch.utils.data import DataLoader, Dataset
from torchvision import transforms
from torchvision.transforms.functional import center_crop
from torchvision.utils import make_grid
from tqdm.auto import tqdm
Uncomment the below code to download the dataset
!wget http://efrosgans.eecs.berkeley.edu/pix2pix/datasets/facades.tar.gz
!tar -xvf facades.tar.gz
After downloading the dataset we create Dataloader which loads our conditional and real image.
path = "./facades/train/"
class FacadesDataset(Dataset):
def __init__(self, path, target_size=None):
self.filenames = glob(str(Path(path) / "*"))
self.target_size = target_size
def __len__(self):
return len(self.filenames)
def __getitem__(self, idx):
filename = self.filenames[idx]
image = Image.open(filename)
image = transforms.functional.to_tensor(image)
image_width = image.shape[2]
real = image[:, :, : image_width // 2]
condition = image[:, :, image_width // 2 :]
target_size = self.target_size
if target_size:
condition = nn.functional.interpolate(condition, size=target_size)
real = nn.functional.interpolate(real, size=target_size)
return real, condition
In the first part of U-Net shaped network the layer size decreases, we create a DownSampleConv module for this. This module will contain the unit block that we just created ConvBlock.
class DownSampleConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel=4, strides=2, padding=1, activation=True, batchnorm=True):
"""
Paper details:
- C64-C128-C256-C512-C512-C512-C512-C512
- All convolutions are 4×4 spatial filters applied with stride 2
- Convolutions in the encoder downsample by a factor of 2
"""
super().__init__()
self.activation = activation
self.batchnorm = batchnorm
self.conv = nn.Conv2d(in_channels, out_channels, kernel, strides, padding)
if batchnorm:
self.bn = nn.BatchNorm2d(out_channels)
if activation:
self.act = nn.LeakyReLU(0.2)
def forward(self, x):
x = self.conv(x)
if self.batchnorm:
x = self.bn(x)
if self.activation:
x = self.act(x)
return x
Now in the second part the network expands and so we create UpSampleConv
class UpSampleConv(nn.Module):
def __init__(
self,
in_channels,
out_channels,
kernel=4,
strides=2,
padding=1,
activation=True,
batchnorm=True,
dropout=False
):
super().__init__()
self.activation = activation
self.batchnorm = batchnorm
self.dropout = dropout
self.deconv = nn.ConvTranspose2d(in_channels, out_channels, kernel, strides, padding)
if batchnorm:
self.bn = nn.BatchNorm2d(out_channels)
if activation:
self.act = nn.ReLU(True)
if dropout:
self.drop = nn.Dropout2d(0.5)
def forward(self, x):
x = self.deconv(x)
if self.batchnorm:
x = self.bn(x)
if self.dropout:
x = self.drop(x)
return x
Now the basic blocks of the Pix2Pix generated is created, we create the generator module. Generator is formed of expanding and contracting layers.
The first part network contracts and then expands again, i.e. first we have encoder block and then decoder block.
Below is the encoder-decoder of U-Net network configuration from official paper. Here C denotes the unit block that we created ConvBlock and D denotes Drop Out with value 0.5.
In the decoder, the output tensors from n-i layer of encoder concatenates with i layer of the decoder. Also the first three blocks of the decoder has drop out layers.
Encoder: C64-C128-C256-C512-C512-C512-C512-C512
Decoder: CD512-CD1024-CD1024-C1024-C1024-C512-C256-C128class Generator(nn.Module):
def __init__(self, in_channels, out_channels):
"""
Paper details:
- Encoder: C64-C128-C256-C512-C512-C512-C512-C512
- All convolutions are 4×4 spatial filters applied with stride 2
- Convolutions in the encoder downsample by a factor of 2
- Decoder: CD512-CD1024-CD1024-C1024-C1024-C512 -C256-C128
"""
super().__init__()
# encoder/donwsample convs
self.encoders = [
DownSampleConv(in_channels, 64, batchnorm=False), # bs x 64 x 128 x 128
DownSampleConv(64, 128), # bs x 128 x 64 x 64
DownSampleConv(128, 256), # bs x 256 x 32 x 32
DownSampleConv(256, 512), # bs x 512 x 16 x 16
DownSampleConv(512, 512), # bs x 512 x 8 x 8
DownSampleConv(512, 512), # bs x 512 x 4 x 4
DownSampleConv(512, 512), # bs x 512 x 2 x 2
DownSampleConv(512, 512, batchnorm=False), # bs x 512 x 1 x 1
]
# decoder/upsample convs
self.decoders = [
UpSampleConv(512, 512, dropout=True), # bs x 512 x 2 x 2
UpSampleConv(1024, 512, dropout=True), # bs x 512 x 4 x 4
UpSampleConv(1024, 512, dropout=True), # bs x 512 x 8 x 8
UpSampleConv(1024, 512), # bs x 512 x 16 x 16
UpSampleConv(1024, 256), # bs x 256 x 32 x 32
UpSampleConv(512, 128), # bs x 128 x 64 x 64
UpSampleConv(256, 64), # bs x 64 x 128 x 128
]
self.decoder_channels = [512, 512, 512, 512, 256, 128, 64]
self.final_conv = nn.ConvTranspose2d(64, out_channels, kernel_size=4, stride=2, padding=1)
self.tanh = nn.Tanh()
self.encoders = nn.ModuleList(self.encoders)
self.decoders = nn.ModuleList(self.decoders)
def forward(self, x):
skips_cons = []
for encoder in self.encoders:
x = encoder(x)
skips_cons.append(x)
skips_cons = list(reversed(skips_cons[:-1]))
decoders = self.decoders[:-1]
for decoder, skip in zip(decoders, skips_cons):
x = decoder(x)
# print(x.shape, skip.shape)
x = torch.cat((x, skip), axis=1)
x = self.decoders[-1](x)
# print(x.shape)
x = self.final_conv(x)
return self.tanh(x)
Discriminator
A discriminator is a ConvNet which learns to classify images into discrete labels. In GANs, discriminators learns to predict whether the given image is real or fake. PatchGAN is the discriminator used for Pix2Pix. Its architecture is different from a typical image classification ConvNet because of the output layer size. In convnets output layer size is equal to the number of classes while in PatchGAN output layer size is a 2D matrix.
Now we create our Discriminator - PatchGAN. In this network we use the same DownSampleConv module that we created for generator.
class PatchGAN(nn.Module):
def __init__(self, input_channels):
super().__init__()
self.d1 = DownSampleConv(input_channels, 64, batchnorm=False)
self.d2 = DownSampleConv(64, 128)
self.d3 = DownSampleConv(128, 256)
self.d4 = DownSampleConv(256, 512)
self.final = nn.Conv2d(512, 1, kernel_size=1)
def forward(self, x, y):
x = torch.cat([x, y], axis=1)
x0 = self.d1(x)
x1 = self.d2(x0)
x2 = self.d3(x1)
x3 = self.d4(x2)
xn = self.final(x3)
return xn
Loss function used in Pix2Pix are Adversarial loss and Reconstruction loss. Adversarial loss is used to penalize the generator to predict more realistic images. In conditional GANs, generators job is not only to produce realistic image but also to be near the ground truth output. Reconstruction Loss helps network to produce the realistic image near the conditional image.
adversarial_loss = nn.BCEWithLogitsLoss()
reconstruction_loss = nn.L1Loss()
# https://stackoverflow.com/questions/49433936/how-to-initialize-weights-in-pytorch
def _weights_init(m):
if isinstance(m, (nn.Conv2d, nn.ConvTranspose2d)):
torch.nn.init.normal_(m.weight, 0.0, 0.02)
if isinstance(m, nn.BatchNorm2d):
torch.nn.init.normal_(m.weight, 0.0, 0.02)
torch.nn.init.constant_(m.bias, 0)
def display_progress(cond, fake, real, figsize=(10,5)):
cond = cond.detach().cpu().permute(1, 2, 0)
fake = fake.detach().cpu().permute(1, 2, 0)
real = real.detach().cpu().permute(1, 2, 0)
fig, ax = plt.subplots(1, 3, figsize=figsize)
ax[0].imshow(cond)
ax[2].imshow(fake)
ax[1].imshow(real)
plt.show()
class Pix2Pix(pl.LightningModule):
def __init__(self, in_channels, out_channels, learning_rate=0.0002, lambda_recon=200, display_step=25):
super().__init__()
self.save_hyperparameters()
self.display_step = display_step
self.gen = Generator(in_channels, out_channels)
self.patch_gan = PatchGAN(in_channels + out_channels)
# intializing weights
self.gen = self.gen.apply(_weights_init)
self.patch_gan = self.patch_gan.apply(_weights_init)
self.adversarial_criterion = nn.BCEWithLogitsLoss()
self.recon_criterion = nn.L1Loss()
def _gen_step(self, real_images, conditioned_images):
# Pix2Pix has adversarial and a reconstruction loss
# First calculate the adversarial loss
fake_images = self.gen(conditioned_images)
disc_logits = self.patch_gan(fake_images, conditioned_images)
adversarial_loss = self.adversarial_criterion(disc_logits, torch.ones_like(disc_logits))
# calculate reconstruction loss
recon_loss = self.recon_criterion(fake_images, real_images)
lambda_recon = self.hparams.lambda_recon
return adversarial_loss + lambda_recon * recon_loss
def _disc_step(self, real_images, conditioned_images):
fake_images = self.gen(conditioned_images).detach()
fake_logits = self.patch_gan(fake_images, conditioned_images)
real_logits = self.patch_gan(real_images, conditioned_images)
fake_loss = self.adversarial_criterion(fake_logits, torch.zeros_like(fake_logits))
real_loss = self.adversarial_criterion(real_logits, torch.ones_like(real_logits))
return (real_loss + fake_loss) / 2
def configure_optimizers(self):
lr = self.hparams.learning_rate
gen_opt = torch.optim.Adam(self.gen.parameters(), lr=lr)
disc_opt = torch.optim.Adam(self.patch_gan.parameters(), lr=lr)
return disc_opt, gen_opt
def training_step(self, batch, batch_idx, optimizer_idx):
real, condition = batch
loss = None
if optimizer_idx == 0:
loss = self._disc_step(real, condition)
self.log('PatchGAN Loss', loss)
elif optimizer_idx == 1:
loss = self._gen_step(real, condition)
self.log('Generator Loss', loss)
if self.current_epoch%self.display_step==0 and batch_idx==0 and optimizer_idx==1:
fake = self.gen(condition).detach()
display_progress(condition[0], fake[0], real[0])
return loss
Now that the network is implemented now we are ready to train. You can also modify the dataloader and train on custom dataset.
Recently I contributed to Pytorch Lightning and now the Pix2Pix model is also available on Pytorch Lightning Bolts, feel free to try that out as well. Hope you liked the article! Happy training 😃
dataset = FacadesDataset(path, target_size=target_size)
dataloader = DataLoader(dataset, batch_size=batch_size, shuffle=True)
pix2pix = Pix2Pix(3, 3, learning_rate=lr, lambda_recon=lambda_recon, display_step=display_step)
trainer = pl.Trainer(max_epochs=1000, gpus=1)
trainer.fit(pix2pix, dataloader)

